kNNs and Decision Trees
kNNs and Decision Trees
kNNs (k-Nearest Neighbors)
先来个Classify的例子

选D:
首先,设有两个向量A和B,它们的点积的定义是:
于是我们有:

So the max dot product is 56 for Green, which means that the Red triangle and the Green diamond point are most consistent in direction.
What is the value of k in kNN?
As k increases, more neightbors get a vote in the prediction.
- more votes = more stability
- more votes = more dis-similar neighbors = less accuracy
How to choose k?
Cross-validation
10-fold Cross Validation to pick k

大意就是:
- 把数据集分成10组
- 对于每个
k,训练10次,每次用9组训练,1组测试【比如第一次是D1作验证集,D2-D10作训练集;第二次是D2作验证集,D1+D3-D10作训练集...】 - average the accuracy
- 选出使得accuracy最大的那个
k
Regression vs. Classification
Regression 用在 Classification上
有的时候,我们也是会把Regression model用在Classification任务上的。
- 先预测数值
- 根据阈值将其binning(分组)成Classification结果
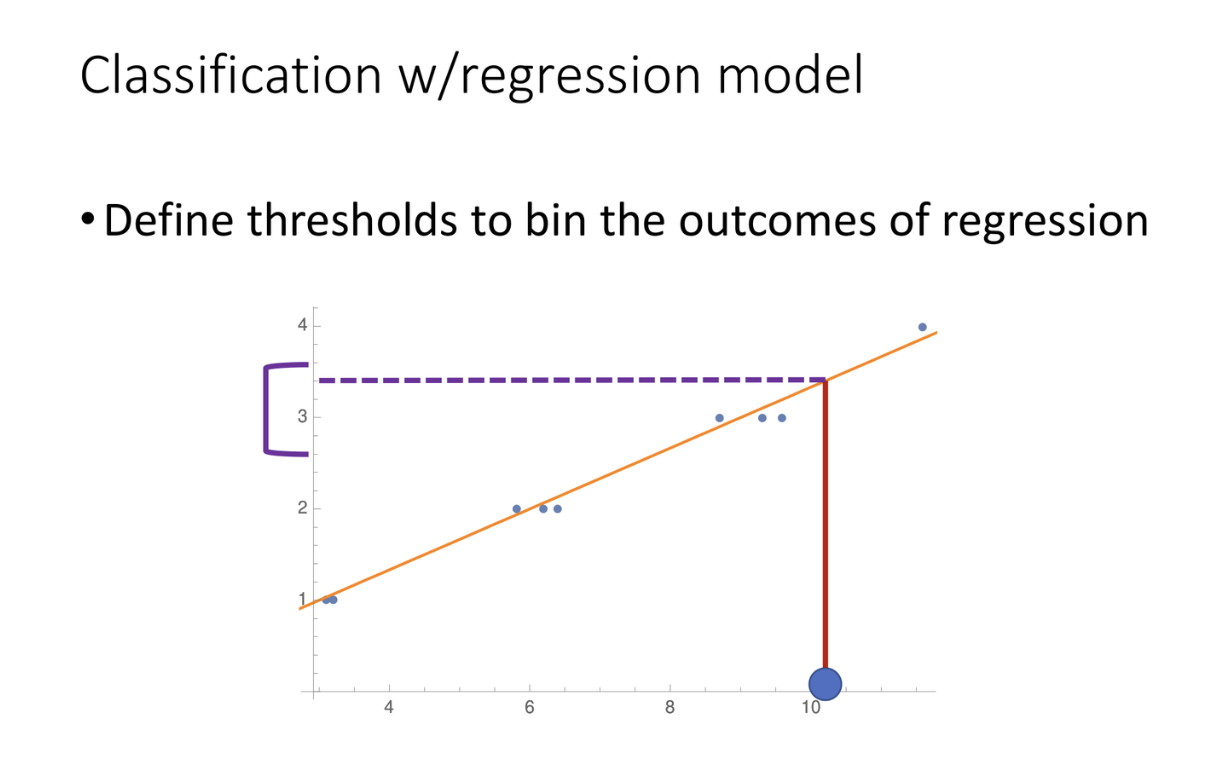
如图,这个大蓝点的prediction是在2.5和3.5之间,我们就把它归到3这个组里。
tip
所以自然,我们也能用回归模型来预测某一个类别的概率,如下Sigmoid/Logistic函数:
Classification 用在 Regression上
kNN也能做回归:
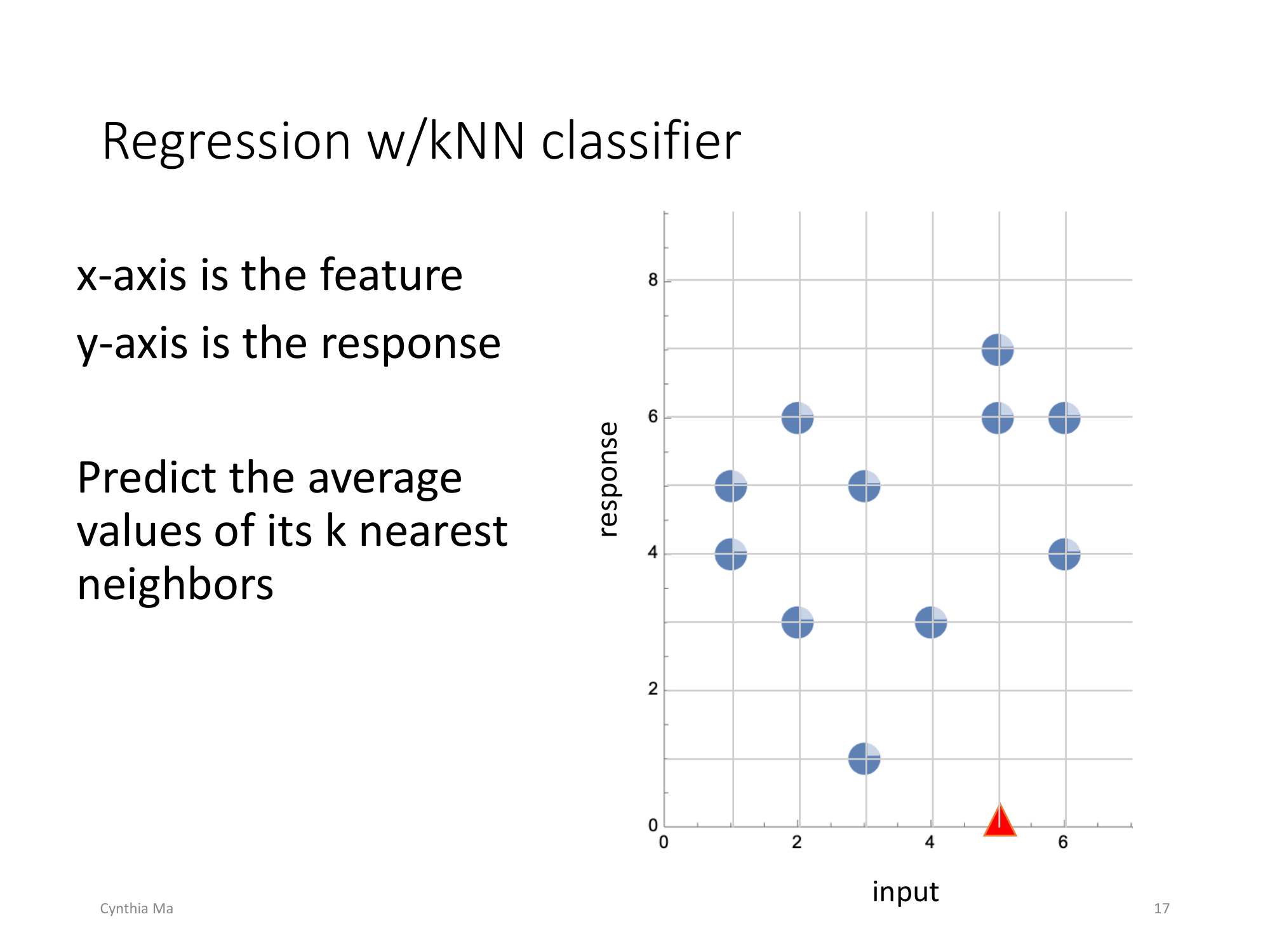
如图,x是feature,y是response.
所以当k=2时,我们计算最近的两个neighbor就是同样x=5的两个点。--> 对红三角的预测y值为(6+7)/2 = 6.5
Decision Trees
Build a Decision Tree
- 选择一个属性作为判定条件,将数据分裂成两部分
- 每个子集重复分裂,直到:
-
- 数据足够纯净
-
- 没有特征可分了
-
- 对每个叶子节点:
-
- 分类树 - 使用多数投票
-
- 回归树 - 使用平均值
-
Optimization of Classification Tree
目标:提高每层纯度。
Gini 不纯度 (Gini Impurity):
越小表示越纯
Optimization of Regression Tree
目标:减少预测误差。 误差(MSE / variance):
Evaluation
其中,Socre就是Gini或Error
例题:
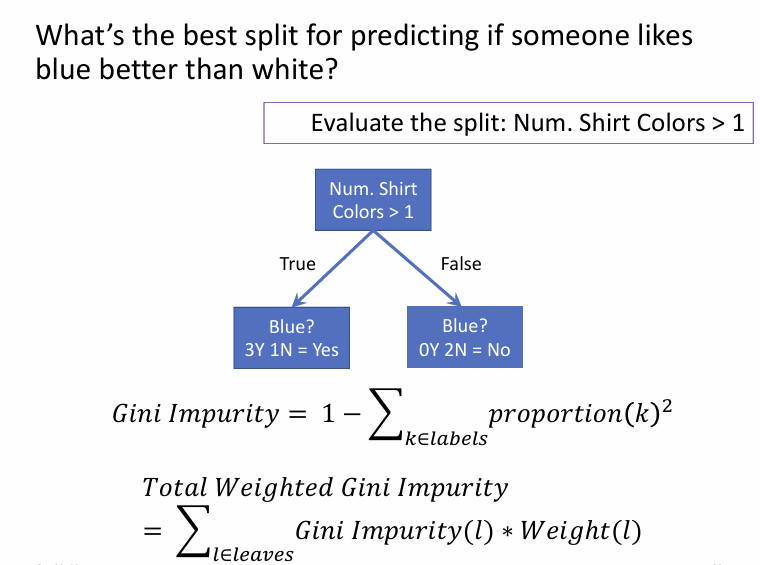
剪枝 (Tree Pruning) 【估计可以忽略
in which,
- is the number of leaves in the tree.
- is a hyperparameter.

Comparison
- Can predict the response / label for a new data?
- kNN: Y
- Decision Tree: Y
- Easy to interpret? (Using intuitive logic)
- kNN:
N. kNN只能说“找邻居”,没法直观解释内部机制 - Decision Tree: Y
- Defines real relationships b/w features and response?
- kNN:
N. 没有明确建模特征间的关系,仅靠距离判断“像不像” - Decision Tree: Y. 通过树的分裂条件,能看出特征间的关系
- Model is fast / easy to store / share / optimize/ apply?
- kNN:
N. 需要存储所有数据点;预测时还得计算所有距离 - Decision Tree: Y. 只需要存储树的结构(路径)和参数
- Few hyperparameters?
- kNN: Y. 只有一个k,也算很少了
- Decision Tree: Y. 可以一个都没有。当然剪枝啥的也可以有
- Use data with minimal preprocessing?
- kNN:
N. 需要标准化数据,避免距离计算时某个特征占主导地位 - Decision Tree: Y.
- Potentially useful?
- kNN:
Y/N?. 准确率不错,但还是老问题 - 难以解释 - Decision Tree: Y. 路径摆在那,随便提出“如果...就...”的建议
- Used to validate a hypothesis?
- Find novel interpretation of data?
- kNN:
N. 无结构无模型 - Decision Tree: Y.